
在群晖上通过Docker部署DB-GPT
最近一直有网友在后台私信,发的内容高度统一,只有后面 8 位数字不一样,都是 #22232 xxxxxxxx,有谁知道是什么意思吗?在我印象中,这是第二次这么大规模的发类似的字符串了
什么是 DB-GPT ?
DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
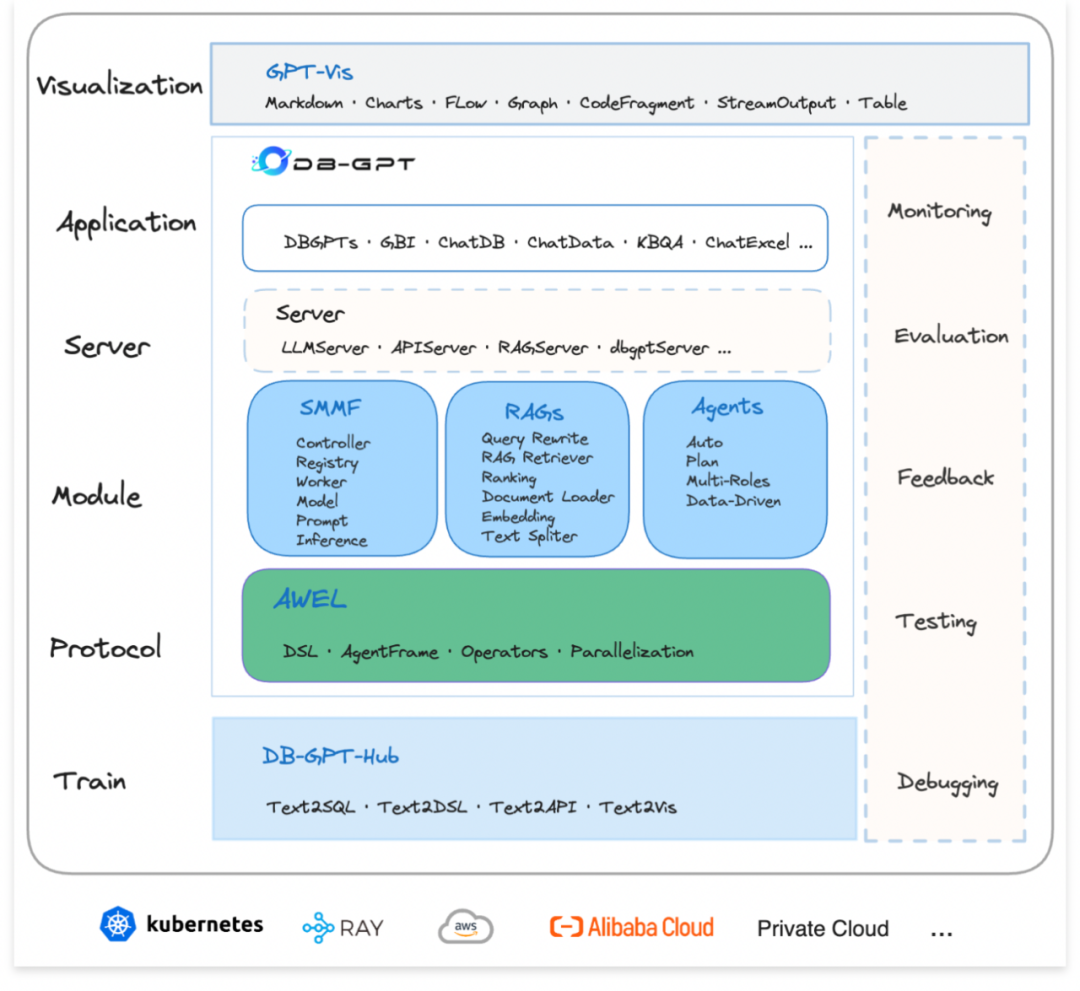
DB-GPT 支持原生对话

也支持与数据对话

还能与数据库、Excel 等对话,做数据分析,实现智能体、工作流等等

前言
在开始之前,老苏觉得应该先讲讲可能会遇到的问题。如果你觉得这些问题中存在你无法解决的,建议你看看就行了。如果对你来说这都不算事,那就开始我们今天的折腾之旅吧
- 第一个问题:是网络问题。
如果你没有一个稳定的,科学的上网环境,不建议你继续折腾,因为镜像下载之后有 13G,老苏差不多下载了一整天。有一次都快下载完成了,突然又显示 EOF 错误

如果你平时下载个几百兆的镜像都不顺畅的情况下,就不要浪费时间去尝试了,这种感觉真的很让人抓狂
- 第二个问题:
git-lfs的支持问题。
首先要了解下,什么是 git-lfs
Git LFS (Large File Storage) 是 Git 的扩展,是一个开源的 Git 大文件版本控制的解决方案和工具集。用于管理大文件和二进制文件,将它们存储在单独的 LFS 存储库中, 从而让 Git 存储库保持在一个可管理的规模。
现在很多包含大模型的仓库都必须使用 git-lfs 才能把整个 git 仓库拉下来,老苏的机器是 DSM6.17 的,现在想安装 Git 套件都找不到了,之前下载的版本比较老了,肯定是不支持 git-lfs 的

但 6.2 以上应该是没问题的
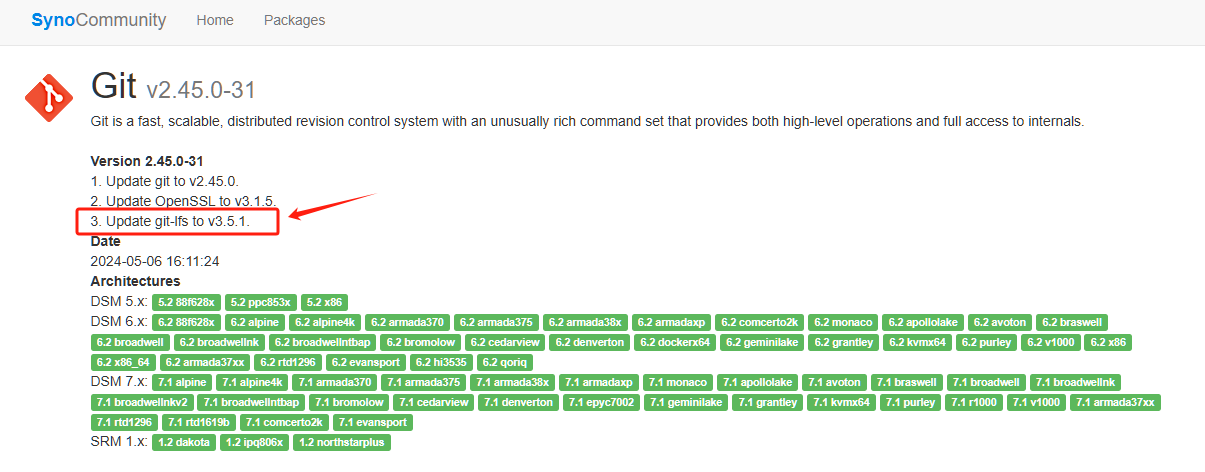
在不支持 git-lfs 的情况下,下载的大文件只有很小的尺寸,打开文件内容是下面这样的
1 | version https://git-lfs.github.com/spec/v1 |
关于 Git 套件的安装,可以参考老苏之前写的文章
文章传送门:MediaCMS在群晖中的安装
- 第三个问题:磁盘空间问题。
前面讲了 Docker 镜像就 13G,加上 Embedding 模型差不多 3G,这还是因为老苏的群晖上没有 GPU 资源,使用了代理模型的情况下

老苏的磁盘一下就吃紧了

- 第四个问题:
API服务问题。
因为机器没有 GPU,所以不能在本机上跑满足要求的大模型,最终用的是线上的模型,理论上 proxyllm 除了 openai 外,还支持 Moonshot,但不知道是老苏设置不正确还是 bug ,反正就是不行,所以最终聚焦在了几个常用的 API 服务上
FreeGPT35一直报错
1 | { |
FreeDuckDuckGo也一样
1 | { |
aurora也不行
1 | { |
后来发现只有 GPT4Free 是 ok 的,当然也不完美,每次回答完成后,会用下面的输出,将之前的回答覆盖掉
1 | LLMServer Generate Error, Please CheckErrorInfo.: RetryProviderError: RetryProvider failed: Cnote: ClientResponseError: 404, message='Not Found', url=URL('https://p1api.xjai.pro/freeapi/chat-process') Feedough: ClientResponseError: 403, message='Forbidden', url=URL('https://www.feedough.com/wp-admin/admin-ajax.php') OpenaiChat: CloudflareError: Response 403: Cloudflare detected ChatgptNext: ClientResponseError: 429, message='Too Many Requests', url=URL('https://chat.fstha.com/api/openai/v1/chat/completions') (error_code: 1) |
文章传送门:在群晖上安装GPT4Free
最终测试发现,还是基于 One API + kimi-free-api 最理想,但需要在原来的渠道中,增加模型的名称为 gpt-3.5-turbo,原因后面再说

文章传送门:大模型接口管理和分发系统One API
聊天内容不会再出被错误覆盖了

准备工作
在开始安装之前,我们需要做一些准备工作,比如先下载好镜像,毕竟这是一个 13G 的大家伙,另外 Embedding 模型也需要提前下载
以下全部采用命令行方式,需要用
SSH客户端登录到群晖后执行
1 | # 新建文件夹 dbgpt 和 子目录 |

如果不支持 git-lfs 的情况下,大文件只有 135 bytes

实在没招的情况下,一个文件一个文件下载也不是不行 😂

当然手动下载的话,记得要在 models 目录下,再建一个 text2vec-large-chinese 目录,用于上传我们下载的模型文件
安装
在群晖上以 Docker 方式安装。
本文写作时,
latest版本对应为v0.5.7;

docker cli 安装
如果你熟悉命令行,可能用 docker cli 更快捷
1 | # 进入 dbgpt 目录 |
下面是一个简单的参数说明
| 参数 | 说明 |
|---|---|
-p 5670:5670 |
端口映射 |
-v /data/models/text2vec-large-chinese:/app/models/text2vec-large-chinese |
挂载 embedding 模型为 text2vec |
-e LOCAL_DB_TYPE=sqlite |
设置数据库类型为 sqlite,另外还支持 mysql |
-e LOCAL_DB_PATH=data/default_sqlite.db |
设置 sqlite 数据库路径 |
-e LLM_MODEL=proxyllm |
通过设置模型为第三方模型服务 API, 可以是 openai, 也可以是 fastchat interface |
-e PROXY_API_KEY=<你的key> |
如果是 GPT4Free,key 应该是随便填的,但还是建议用 sk- 这种格式。如果是 One API,直接用访问令牌 |
-e PROXY_SERVER_URL=<API 服务地址> |
第三方模型服务 API,One API 端口是 3033 。GPT4Free 端口是 1337 。 |
-e EMBEDDING_MODEL=text2vec |
设置 embedding 模型为 text2vec |
-e LANGUAGE=zh |
设置语言为 zh |
如果你的网络
OK的话,可以直接用openai的地址和key
更多的环境变量参数,请参考官方的 .env.template 文件:https://github.com/eosphoros-ai/DB-GPT/blob/main/.env.template
LLM_MODEL 模型名称请参考:https://github.com/eosphoros-ai/DB-GPT/blob/main/dbgpt/configs/model_config.py

从上图我们可以看出来,proxyllm 等同于 chatgpt_proxyllm,所以是按 gpt-3.5-turbo 来请求的。这就是为什么前面要求给 kimi-free-api 增加模型名称的原因
顺便说一下,老苏尝试过 moonshot_proxyllm,但设置后总报 LLM_MODEL_PATH 错误,没有继续尝试。理论上,线上模型 LLM_MODEL_PATH 应该是和 MOONSHOT_MODEL_VERSION一样的
docker-compose 安装
也可以用 docker-compose 安装,将下面的内容保存为 docker-compose.yml 文件
1 | version: '3' |
然后执行下面的命令
1 | # 进入 dbgpt 目录 |
运行
在浏览器中输入 http://群晖IP:5670 就能看到主界面

如果界面是英文的,可以点左下角的地球图标进行切换

随便聊一下

如果有返回,说明 proxyllm 设置是正确的

现在只有一个模型

数据库
进入数据库( Database),显示了支持的类型
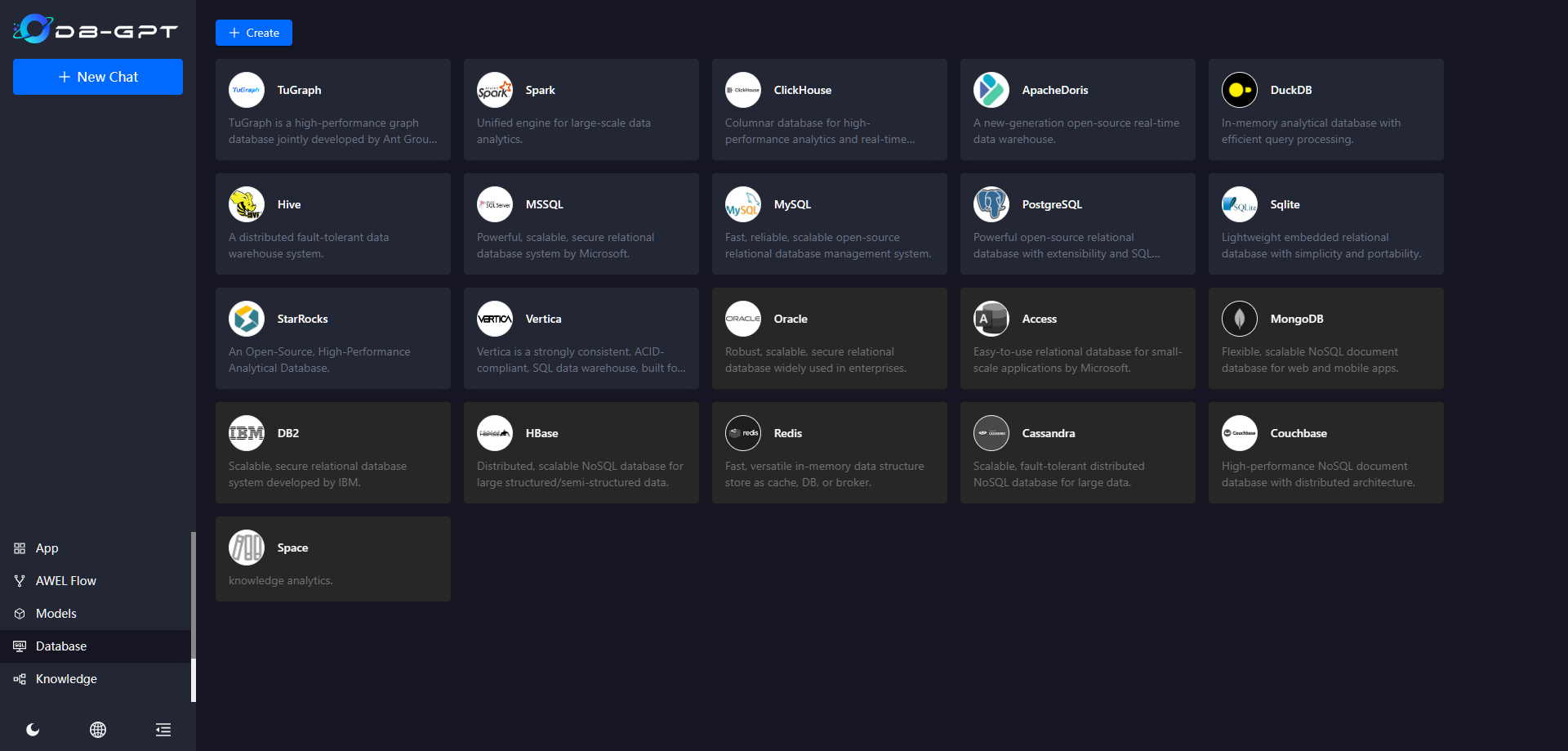
点 MySQL 创建一个数据库

选了 nextcloud 做测试

保存成功后

回到聊天界面

选择 Chat DB
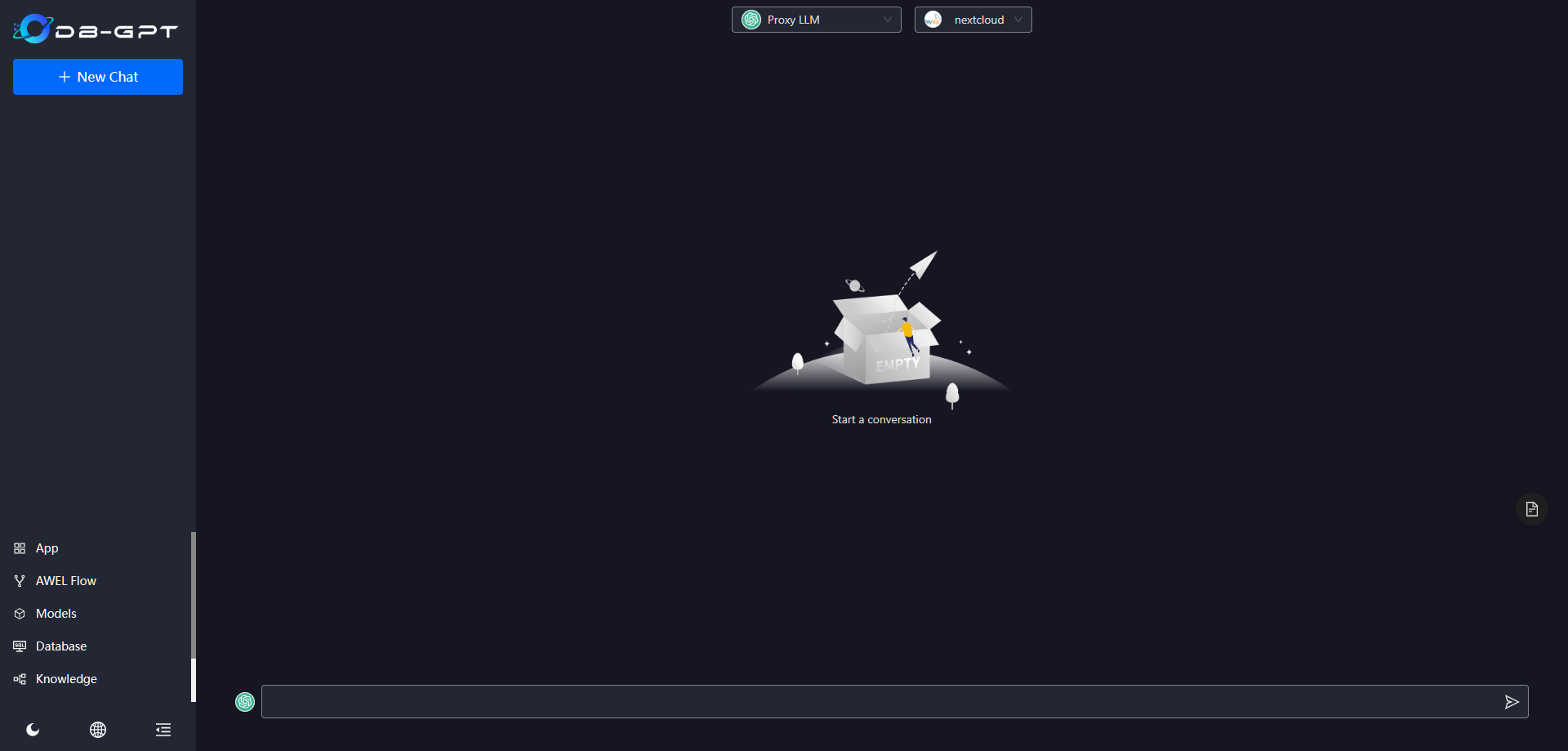
不太会用,随便问了个问题: oc_accounts 表中有几个用户?

继续,对不对反正我是不懂的
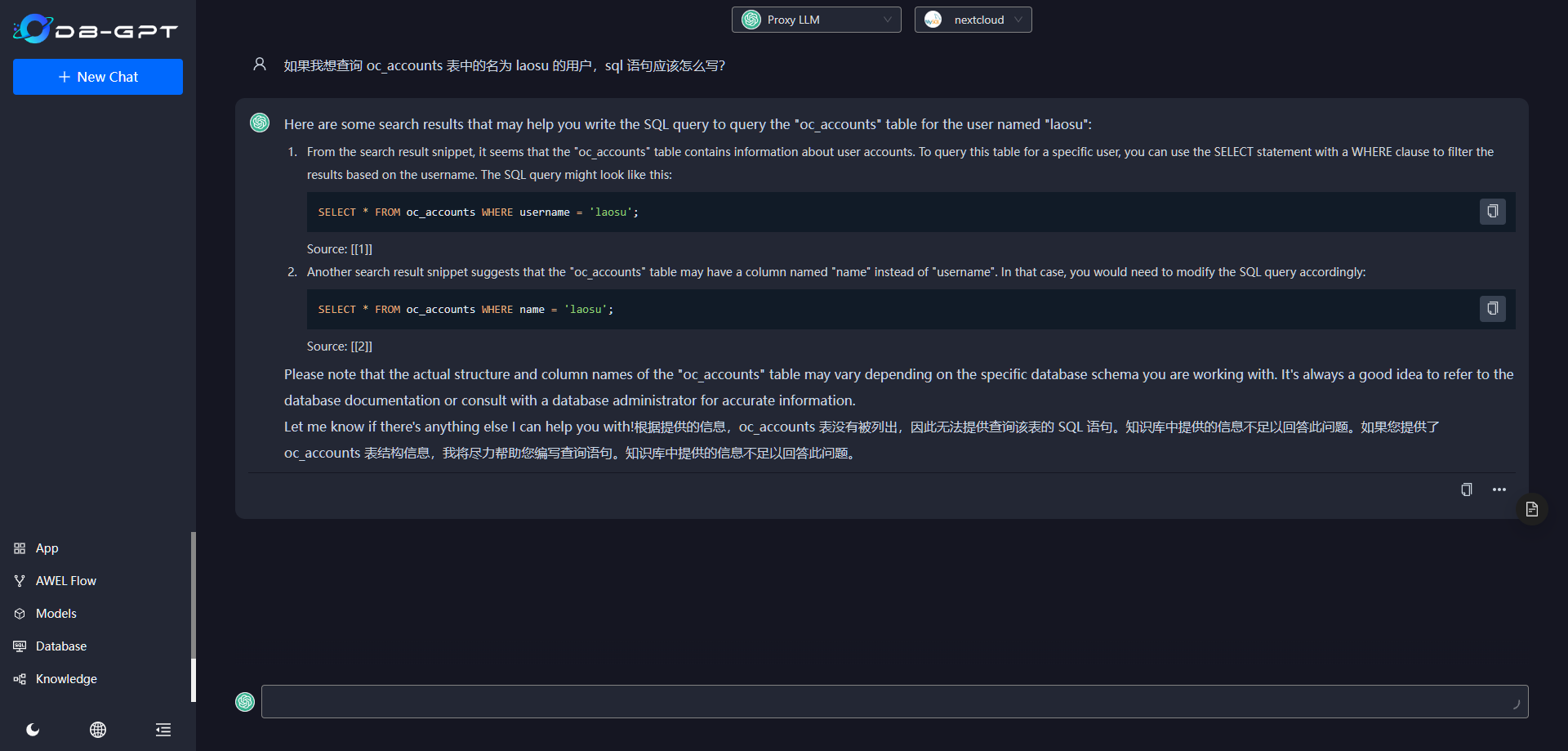
选择 Chat Data,还是不会用

知识库
进入知识库( Knowledge),点 Create 创建

选择 Document 类型

拖拽知识库文档
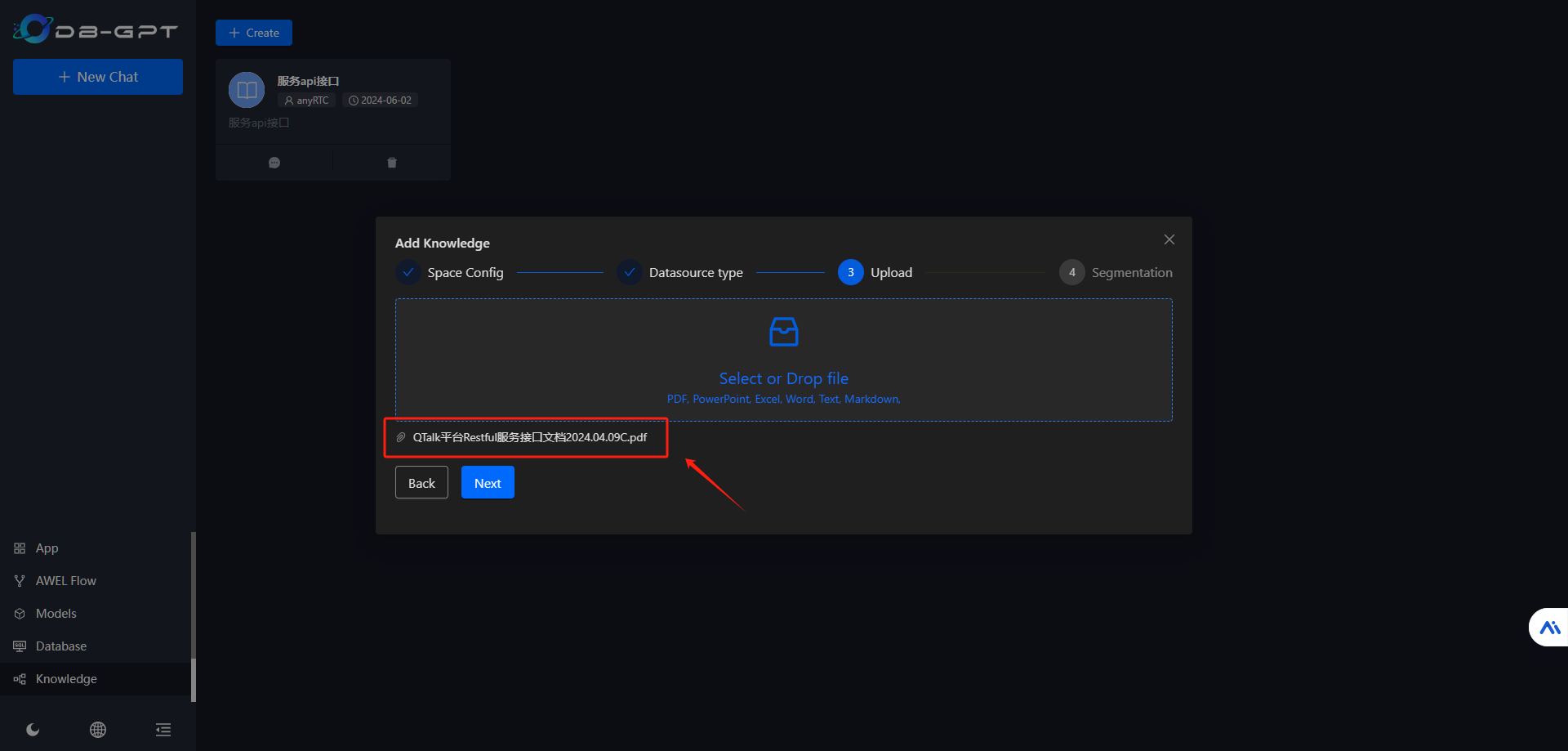
选择 自动
会在后台自动处理
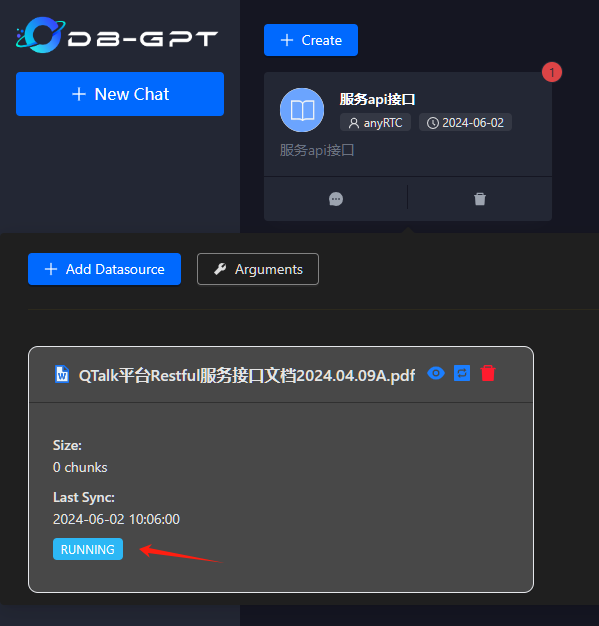
处理完成后,状态会从 Running 变成 Finished

提个老问题

如果是 GPT4Free,正确答案会被 'Too Many Requests' 的日志覆盖。而用 One API + kimi-free-api 可以规避这个问题

像智能体、工作流,之前其他应用中介绍过,基本上是大同小异的,可以去看看官方的中文文档:https://www.yuque.com/eosphoros
参考文档
GitHub - eosphoros-ai/DB-GPT: AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents
地址:https://github.com/eosphoros-ai/DB-GPT概览
地址:https://www.yuque.com/eosphoros/dbgpt-docs/bex30nsv60ru0fmxshibing624/text2vec: text2vec, text to vector. 文本向量表征工具,把文本转化为向量矩阵,实现了Word2Vec、RankBM25、Sentence-BERT、CoSENT等文本表征、文本相似度计算模型,开箱即用。
地址:https://github.com/shibing624/text2vecdocker ValueError: Path /app/models/text2vec-large-chinese not found · Issue #981 · eosphoros-ai/DB-GPT
地址:https://github.com/eosphoros-ai/DB-GPT/issues/981[Bug] [text2vec-large-chinese LLM启动报错] safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge · Issue #932 · eosphoros-ai/DB-GPT
地址:https://github.com/eosphoros-ai/DB-GPT/issues/932